1 sana-profiling
Profiling mirrors a benchmark task into a LakeQA-style EQA task and a matching runtime profile — the artifact that powers every idealized tool. A profile records:
source_sequence/dataset_sequence— the ordered gold sources each step needs.reasoning_chain_text— the answer-safe decomposition (sub-questions that don't leak which dataset to fetch).ideal_query/ideal_code— per node: the intent, the verified SQL or Python, and the gold intermediate answer.
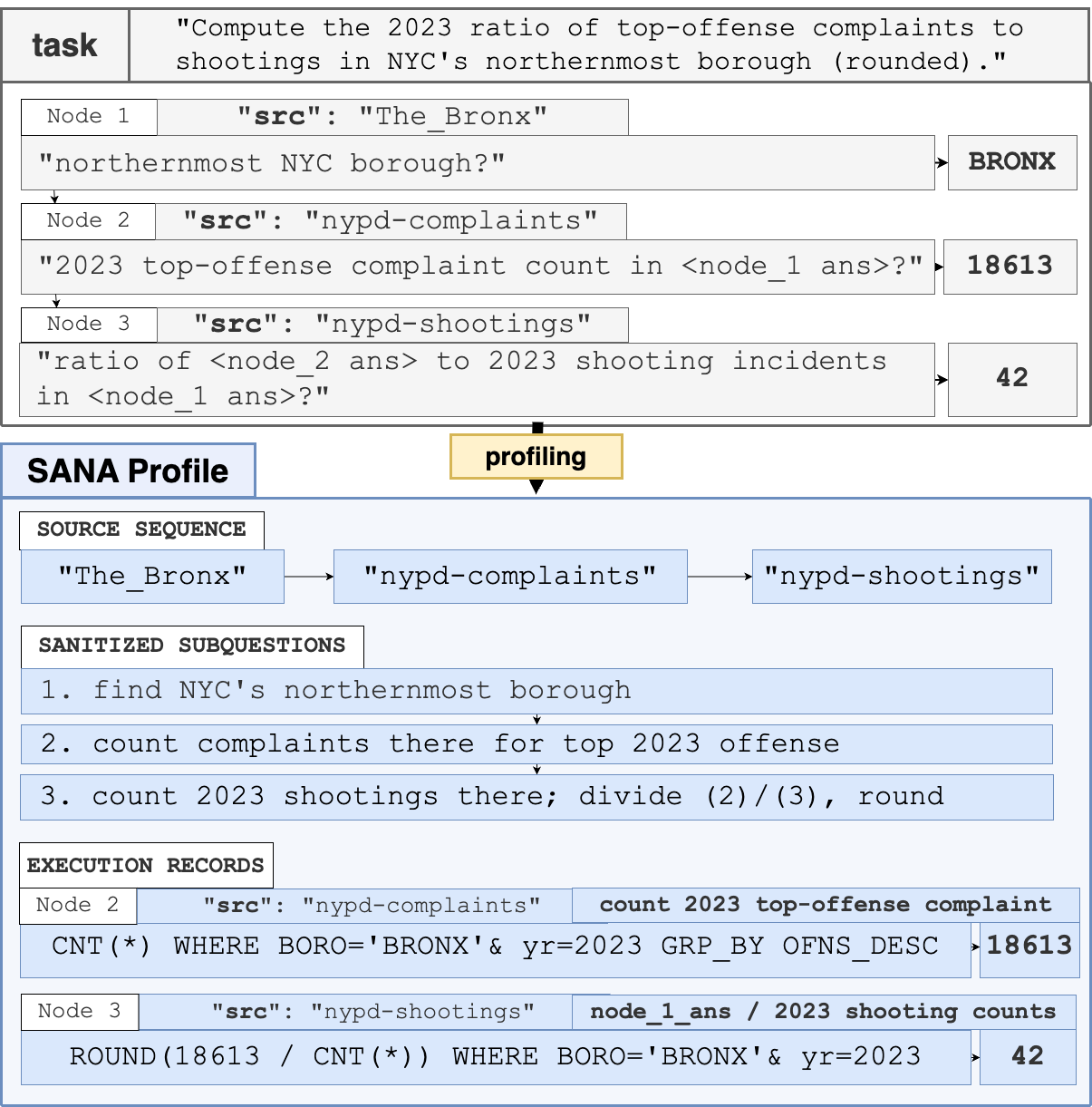
The profile is what each ideal mode draws on at evaluation time:
--profile ideal
Exposes the gold reasoning chain as an explicit, answer-safe decomposition.
--search ideal
Returns exactly the gold sources each query needs from the source sequence — nothing irrelevant.
--compute ideal
Runs the profile's ideal SQL/Python — no implementation error, exactly as the agent intended.
LakeQA and KramaBench ship ready-made tasks, profiles, and artifacts. Converting a new benchmark is report-first: sample examples, scaffold a transform skill, then run it.